Article Disaster Recovery in AWS

By Insight UK / 27 Mar 2019 / Topics: Cloud
With regards to IT infrastructure, a disaster is a sudden accident or a natural catastrophe that causes disruption to the services provided by the IT systems. Examples of these include: accidental data deletion, hardware and software failure, network downtime, power outage, and flooding or fire incident in the data centre.
To ensure business continuity, companies require a plan of action to respond to a disaster and eliminate the risk of losing business and reducing employee productivity. Disaster Recovery (DR) is about establishing an IT strategy that will be deployed in the event of a disaster. Traditionally, this is achieved by building two or more discrete data centres, each with redundant power, networking, and connectivity, housed in separate facilities. The data centres will be running the same applications and data across them either in active-active mode or active-passive mode. Under normal operation, only one of the data centres is utilised hence the resources in other data centres are often under-utilised and over-provisioned.
However, with AWS, this does not have to be the case. Companies can take advantage of the AWS global infrastructure to implement a DR strategy without the need to build multiple data centres. The pay-as-you-go model, flexibility, scalability and reliability of AWS provides the platform to implement a DR strategy tailored to meet set recovery targets.
AWS Disaster Recovery Strategies
The decision on the DR strategy to adopt is dependent on two concepts:
- Recovery Time Objective (RTO)
The time it takes after a disruption to service to restore a business process to its service level. For example, if the RTO of an e-commerce site is two hours and a disaster occurs at 1pm, the DR strategy must kick-in a process to restore the site at 3pm. - Recovery Point Objective (RPO)
The acceptable amount of data that can be lost (measured in time) before causing detrimental harm to the organisation. For example, if the RPO of a financial trading system is 30 minutes and a disaster occurs at 2pm, the DR strategy must kick-in a process to recover all of the data before 1:30pm. Data loss can only span between 1:30pm and 2pm.

Figure 1: Recovery Point Objective (RPO) and Recovery Time Objective (RTO)
The acceptable RTO and RPO values are selected based on the financial and productivity impacts to the business when a disaster occurs. The cost of implementing a DR strategy increases as the values of RTO and RPO reduce. In AWS, there are four major strategies that can be implemented to meet set RTO and RPO targets:
- Backup and Restore
- Pilot Light
- Warm Standby
- Multi-Site
Backup and Restore
This is a traditional method of Disaster Recovery where data is backed up at regular intervals and in the event of a disruption or disaster, data is restored from the backup location. Given the lead time in transferring and restoring data from backup, this method is only suitable where hours of RTO and RPO are acceptable.
In AWS, the Simple Storage Service (S3) with eleven 9's durability, is the ideal storage location for backup. Whether the application is deployed on-premise or in AWS, S3 offers a range of storage classes (including archival storage) for cost-effective backup based on use case scenario and RTO/RPO targets.
Figure 2 below shows the backup of data to S3 from either on-premise infrastructure or from AWS. Workloads running in AWS are backed up by taking snapshots of the storage disks which are natively supported for a majority of the services and stored in S3. For on-premise backup and restore, data can be transferred to and from AWS using the following services:
- AWS Direct Connect or Virtual Private Network (VPN)
- AWS Snowball
- AWS Storage Gateway
- Amazon S3 Transfer Acceleration
- ISV data migration solutions
To facilitate quick recovery in the event of a disaster, the application is pre-configured on an EC2 instance and converted to Amazon Machine Image (AMI) stored in S3. An AMI includes:
- A template for the root volume for the instance (for example, an operating system, an application server, and applications).
- Launch permissions that control which AWS accounts can use the AMI to launch instances.
- A block device mapping that specifies the volumes to attach to the instance when it's launched.
In the event of a disaster, data is retrieved from S3 and a pre-configured AMI is used to recreate the production environment in AWS.

Figure 2: Backup and Restore Implementation on AWS
Pilot Light
This is a Disaster Recovery scenario where a minimal version of an environment is always running on AWS. Pilot light can be implemented by configuring and running the most critical and core elements of the production environment in AWS. In the event of a disaster, a full-scale production environment can be deployed around the critical core elements.
Infrastructure components for pilot light will typically include database servers and Active Directory servers, which will require data replication from on-premise infrastructure to AWS using Elastic Compute Cloud (EC2) instances or native AWS services. To provision the reminder of the environment, AMIs can be utilised to quickly deploy the required compute instances configured with Elastic IP address or using Elastic Load Balancer (ELB) to distribute traffic to multiple instances.
Pilot light gives a much quicker recovery time and recovery point than the backup and restore method because the critical components of the application are always on and kept in sync with the production environment. In a disaster event, the AWS environment can be automated to provision and configure the infrastructure resources to production scale, which minimises errors and helps save time.

Figure 3: Pilot Light Implementation on AWS
Warm Standby
The warm standby approach is used for a DR scenario where a functional version of the production environment is running in the cloud, but in a scaled-down mode. This implies that the environment is not able to support production traffic but can easily be scaled up by adding more compute resources across the application tiers to support production traffic. Warm standby further reduces the recovery time when compared to pilot light by keeping some services always on and ready to be easily scaled up.
For example, an application that requires a load balanced fleet of EC2 instances each with four vCPU cores and 16GB RAM can be configured in warm standby mode to run on a single EC2 instance with two vCPU and 4GB RAM. In a DR scenario, the application can automatically be scaled up to run on right sized EC2 instances configured with autoscaling and load balancer to support production traffic.
Figure 4 below shows the setup for warm standby. Data is replicated to a DR environment on AWS, however, the scaled-down application is referencing the production database which makes it a functional version of the production environment. In the event of a disaster, the slave database server is promoted to master and the application database credentials updated to reference the database in AWS.

Figure 4: Warm Standby Implementation on AWS
Multi-Site
In the multi-site approach, the production environment runs both on the on-premise infrastructure and in AWS in an active-active configuration. This approach gives the best recovery time and data can be replicated using various methods (highlighted in the backup and restore section) to meet the recovery point targets.
To achieve an active-active configuration, a domain name system (DNS) service that supports weighted routing policy (for example Amazon Route53) can be used to send a portion of the traffic to the on-premise infrastructure and the rest to AWS. Similar to the warm standby, both applications will reference the master database server on-premise with data replication to the slave database in AWS.
In the event of a disaster, the routing policy can be updated to send all traffic to AWS where a pre-configured autoscaling group will scale up the EC2 instances to cater for the increased production traffic. A logic will be required to detect the disaster and upgrade the slave database to the master with the database credentials updated in the application layer to reference the database on AWS.
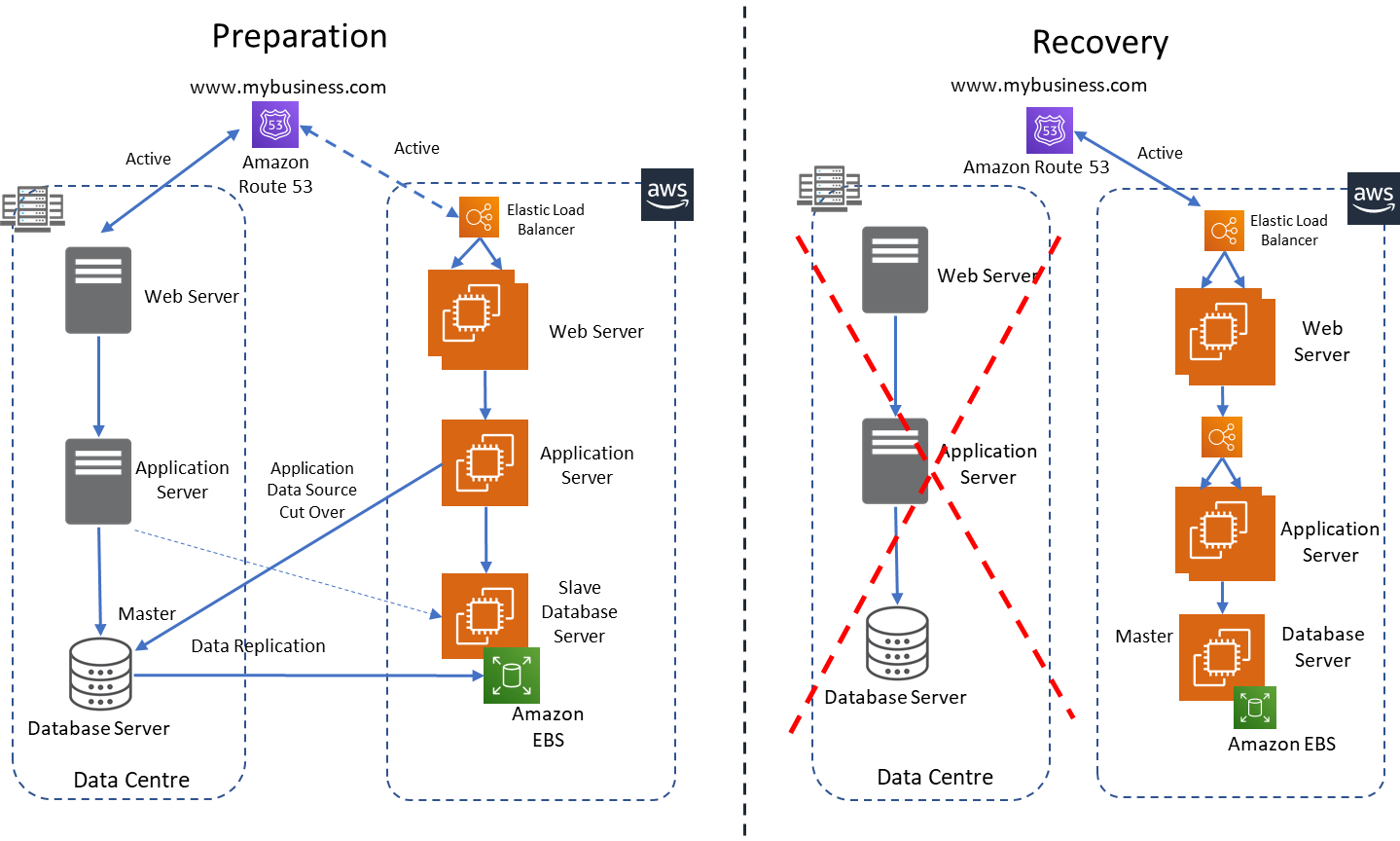
Figure 5: Multi-Site Implementation on AWS
Conclusion
Implementing a Disaster Recovery strategy is no longer a ‘nice to have’ but a key requirement to ensure business continuity and reduce impact to the business and its clients. This implementation can be done either by using an on-site facility (private data centre or co-location) or using the cloud environment (e.g. AWS). However, given the flexibility, scalability, availability and pricing model of AWS, the cloud is a natural fit for DR purposes with low barriers to entry and various implementation options (covered in this article) to meet set RTO and RPO targets.
If you are interested in finding out more about Disaster Recovery in AWS or need help with implementing any of the strategies discussed in this article, please contact your Insight Account Manager or get in touch via our contact form here.



